学习如何用 Python 构建Web Scraper,爬取整个网站并通过网页抓取提取所有重要数据。
网页抓取是从Web网页中提取数据。具体来说,web scraper一般表示为脚本,是一种网页爬虫。 Python 是最简单可靠的可用脚本语言之一;此外,Python还附带了各种各样的网页抓取库。这使得它成为网页抓取的完美编程语言。详细得说,使用Python 只需要几行代码就能实现网页抓取。
在本教程中,您将学习如何构建简单的 Python 爬虫。该应用可以浏览整个网站,从每个页面中提取数据。然后,它会把 Python 抓取的所有数据保存在一个 CSV 文件中。本教程将带您了解最好的 Python 数据抓取库以及如何使用。您可以按照这个分步教程学习构建网页抓取 Python 脚本。
内容目录:
先决条件
要构建 Python Web Scraper,需要满足以下先决条件:
- 下载Python 3.4+
- 安装pip
如果您的计算机上没有安装 Python,可以点击上面第一个链接进行下载。如果您是 Windows 用户,请务必在安装 Python 时勾选“Add python.exe to PATH”,如下所示:
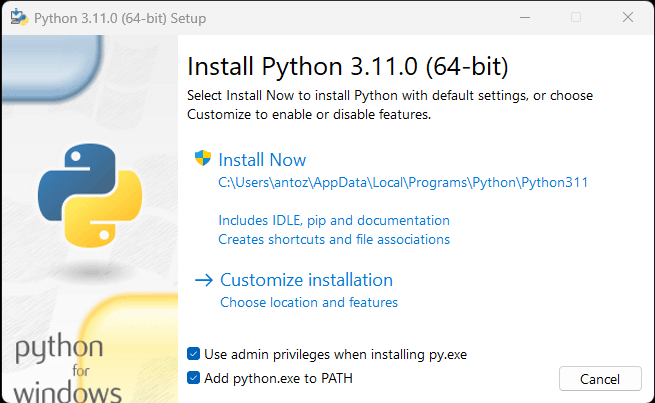
这样操作后,Windows就会自动识别终端中的python和pip命令。详细来说,pip 是 Python 安装包的包管理器。请注意,在 Python 3.4 或更高版本中默认包含pip 。因此,以上版本的Python无需手动安装pip。
到这一步,可以构建第一个 Python Web Scraper。但首先,您需要一个 Python 网页抓取库!
最好的 Python 网页抓取库
您可以使用 Python vanilla 从头开始构建网页抓取脚本,但这不是理想的解决方案。毕竟Python 库选择多且量大。也就是说,我们可以从几个网页抓取库可供选择。现在让我们来看看最重要的库!
Requests请求
requests库允许用户在 Python 中执行 HTTP 请求。详细地说, 有了requests,发送 HTTP 请求更容易,特别是与标准的 Python HTTP 库相比。 requests在 Python 网页抓取项目中起着关键作用。这是因为要抓取网页中的数据,您首先需要通过HTTP GET request 检索数据。此外,您可能还需要向目标网站的服务器执行其他 HTTP 请求。
您可以使用以下 pip 命令安装requests:
pip install requestsBeautiful Soup
requests库允许用户在 Python 中执行 HTTP 请求。详细地说, 有了requests,发送 HTTP 请求更容易,特别是与标准的 Python HTTP 库相比。 requests在 Python 网页抓取项目中起着关键作用。这是因为要抓取网页中的数据,您首先需要通过HTTP GET request 检索数据。此外,您可能还需要向目标网站的服务器执行其他 HTTP 请求。
您可以使用以下 pip 命令安装requests:
pip install beautifulsoup4Selenium
Selenium是一种开源、高级、自动化的测试框架,允许用户在浏览器网页上执行操作。换句话说,您可以使用 Selenium 来指示浏览器执行某些任务。请注意,您还可以将 Selenium 用作网页抓取库,因为它具有无头浏览器功能。如果您对此概念不熟悉,无头浏览器是一种在没有 GUI(图形用户界面)情况下运行的网页浏览器。如果配置为无头模式,Selenium 将在幕后运行浏览器。
因此,能够运行 JavaScript 的真实浏览器会渲染在 Selenium 中访问的网页。因此, Selenium 允许您抓取依赖于JavaScript的网站。请记住,您无法通过requests请求或任何其他 HTTP 客户端实现此目的。这是因为您需要浏览器来运行 JavaScript,而requests请求只能执行 HTTP 请求。
Selenium 满足了构建Web Scraper 所需的一切,无需其他库。您可以使用以下pip命令安装Selenium:
pip install selenium用 Python 构建Web Scraper
现在让我们学习如何在 Python 中构建web scraper。本教程的目的是学习如何提取Quotes to Scrape网站中包含的所有引用数据。您将学习如何抓取引用的每个文本、作者和标签列表。
但首先,让我们了解一下目标网站。这是 Quotes to Scrape 网页:
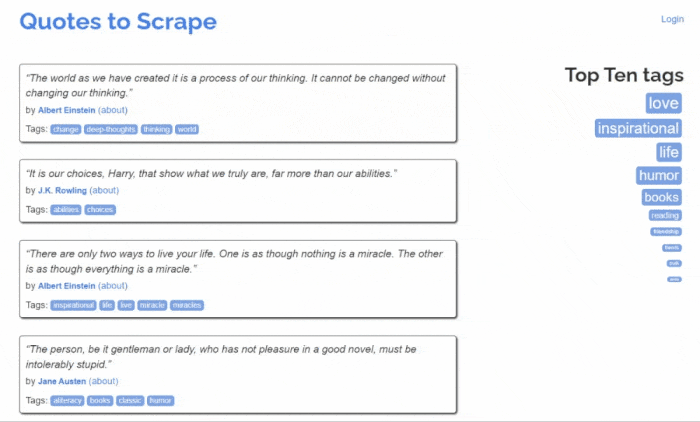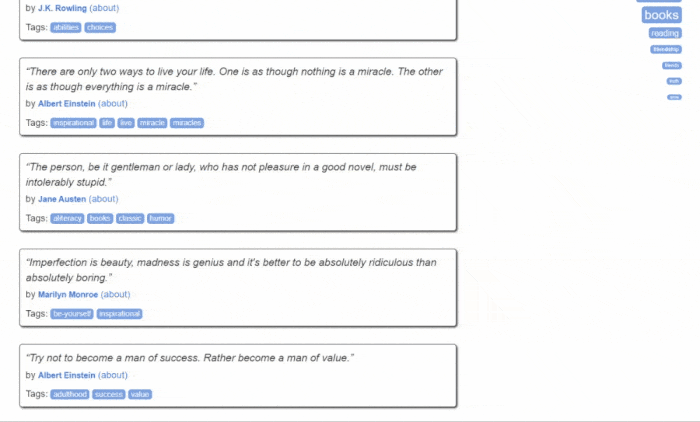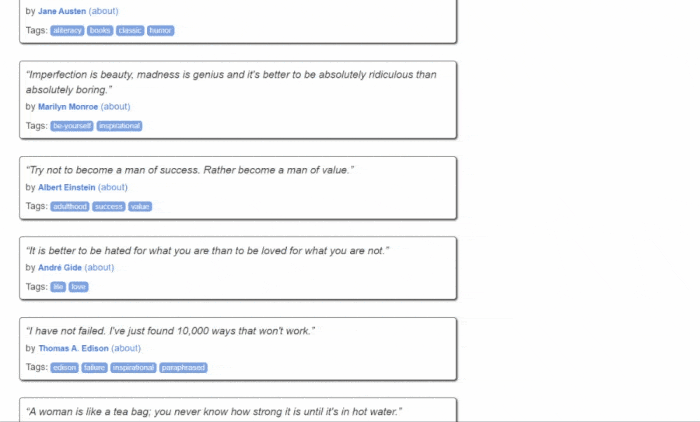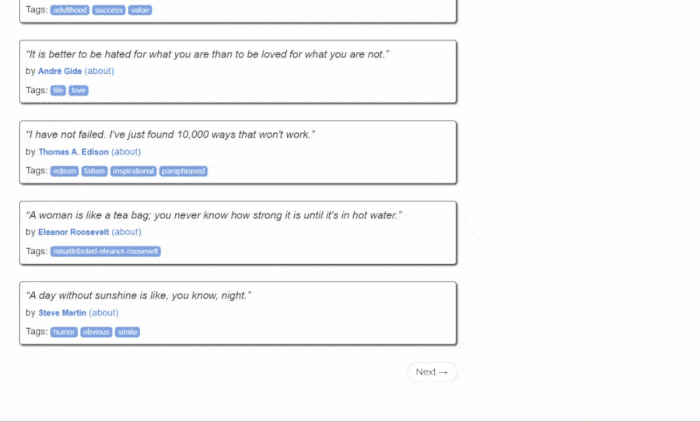
如您所见,Quotes to Scrape 只是一个用于网页抓取的沙箱。具体来说,它包含一个分页的引用列表。您将要构建的 Python web scraper将检索网站每个页面上的所有引用,并返回CSV 数据。
现在,是时候了解实现数据抓取目标的最佳 Python 网页抓取库是哪个了。如下方 Chrome DevTools 窗口的 Network 选项卡所示,目标网站不执行任何Fetch/XHR request请求。
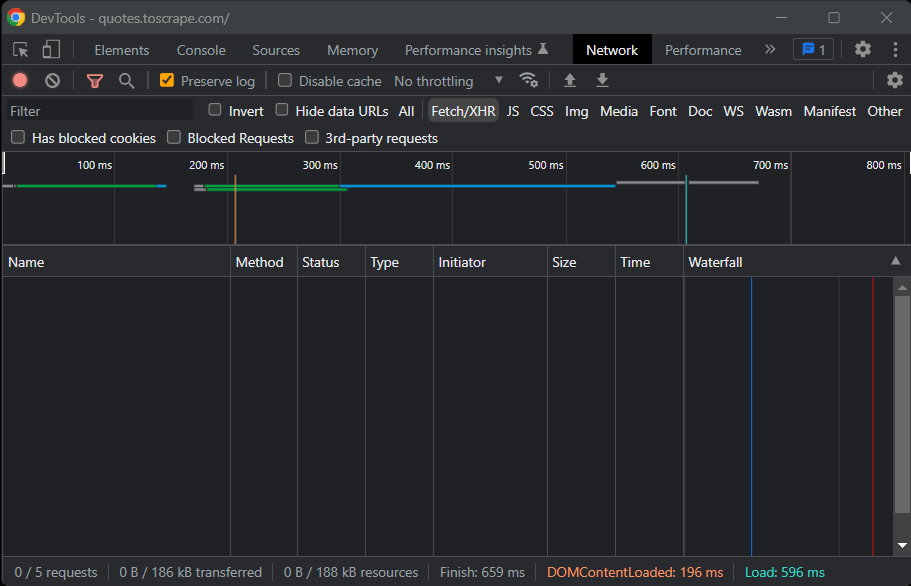
换句话说,Quotes to Scrape 不依赖 JavaScript 来检索网页渲染的数据。这是大多数服务器渲染网站的常见情况。由于目标网站不依赖 JavaScript 来渲染页面或检索数据,因此也不需要使用 Selenium 来抓取数据。您也可以选择使用Selenium,但这不是必需的。
正如之前提到的,Selenium 在浏览器中打开网页。由于这需要时间和资源,Selenium 引入了性能开销。您可以将 Beautiful Soup 与 Requests 一起使用来避免这种情况。现在我们来学习如何构建一个简单的 Python 网页抓取脚本,来使用 Beautiful Soup 从网站检索数据。
准备开始
在开始编写第一行代码之前,您需要设置 Python 网页抓取项目。从技术上讲,您只需要一个.py文件。但是,使用高级 IDE(集成开发环境)会使您的编码体验更加轻松。在这里,您将学习如何在PyCharm 2022.2.3中设置 Python 项目,但使用其他 IDE 也可以设置。
首先,打开 PyCharm 并选择“文件/File > 新项目/New Project…”。在“新项目”弹出窗口中,选择“Pure Python”并初始化您的项目。
例如,您可以将项目命名为python-web-scraper 。单击“创建/create”,您可以访问空白 Python 项目。PyCharm 默认会初始化一个main.py文件。为了更清楚,您可以将其重命名为scraper.py 。您的项目现在看起来是这样的:
如您所见,PyCharm 会自动为您初始化一个 Python 文件。忽略这个文件的内容并删除每一行代码。这样,您就可以从头开始创建项目。
到这一步,可以安装项目的依赖项了。您可以在终端中启动以下命令来安装 Requests 和 Beautiful Soup:
pip install requests beautifulsoup4启动此命令会同时安装这两个库。安装过程完成后,您可以使用 Beautiful Soup 和 Requests 在 Python 中构建您的网页爬虫和抓取工具。将以下几行的内容添加到scraper.py脚本文件的顶部来确保导入这两个库:
import requests
from bs4 import BeautifulSoup由于代码中并未用到这些库,所以这两行内容显示为灰色。如果这两行出现红色下划线,则表示安装过程中出现问题。遇到这种情况,请尝试重新安装。
您当前的scraper.py文件看起来应该是这样。现在您可以开始定义网页抓取逻辑了。
连接到要抓取的目标网页URL
Web Scraper 要做的第一件事是连接到目标网站。首先,从您的网页浏览器检索页面的完整URL。确保复制http://或https:// HTTP 协议部分。如图所示,这是目标网站的完整 URL:
https://quotes.toscrape.com现在,您可以通过以下代码行使用requests来下载网页:
page = requests.get('https://quotes.toscrape.com')这行代码是将request.get()方法的结果分配给变量page/页面 。在后台, request.get()使用 URL ,将其作为参数传递,执行 GET 请求。然后,request.get()会返回一个Response/响应对象,其中包含服务器对 HTTP 请求的响应。
如果 HTTP 请求执行成功,page.status_code会显示状态码200 。这是因为HTTP 200 OK响应状态码表示 HTTP 请求执行成功。 4xx或5xx HTTP响应状态则表示错误。错误发生的原因有很多,但请注意,大多数网站都会阻止没有包含有效User-Agent标头的请求。具体来说, User-Agent请求标头是一个字符串,它描述了请求发起处的应用程序和操作系统版本。点击此处了解使用User-Agents进行网页抓取的更多信息。
您可以在requests请求中设置有效的User-Agent标头,如下图所示:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)设置后,requests将执行 HTTP 请求,并将标头作为参数传递。
您需要注意page.text属性。属性会包含服务器以字符串格式返回的 HTML 文档。将text属性提供给 Beautiful Soup 以从网页中提取数据。我们来学习如何操作。
使用 Python web scraper提取数据
要从网页中提取数据,首先需要识别包含感兴趣的数据的 HTML 元素。具体来说,您必须找到从 DOM 中提取这些元素所需的CSS 选择器。通过使用浏览器提供的开发工具可以实现这一点。在 Chrome 浏览器中,右键点击感兴趣的 HTML 元素并选择Inspect检查。
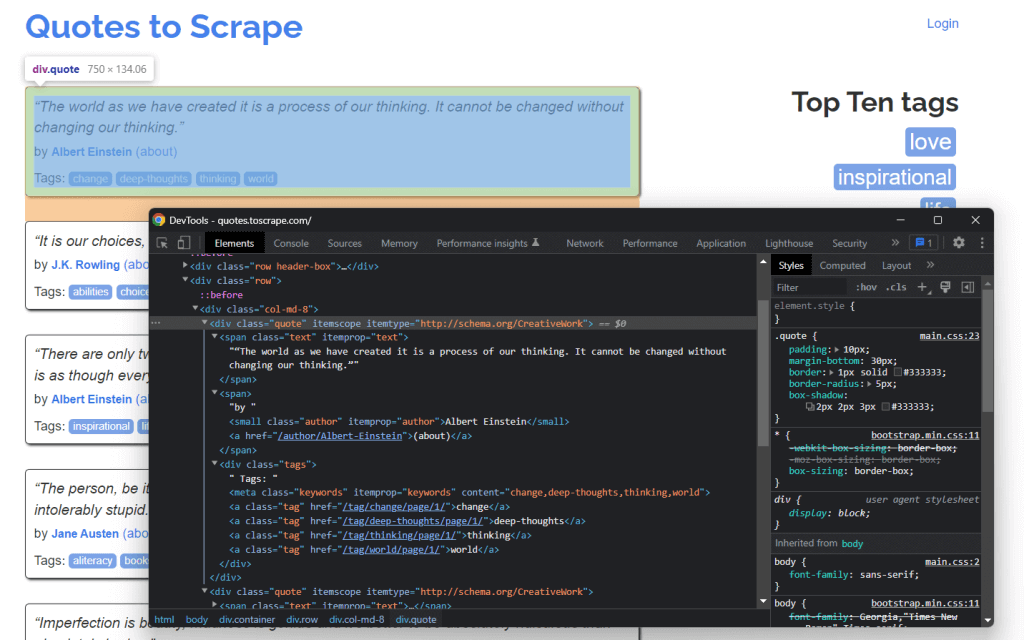
您可以从图上看到, quote <div> HTML HTML 元素由quote/引用类标识。这包含:
<span>HTML元素中的引用文本<small>HTML元素中的引用作者<div>元素中的标签列表,每个标签都包含<a>HTML元素中
详细来说,您可以在 .quote:上使用以下 CSS 选择器提取此数据:
.text.author.tags .tag
现在我们来学习如何使用 Python 的 Beautiful Soup 实现这一目标。首先,我们要将page.text HTML 文档传递给 BeautifulSoup() 构造函数:
soup = BeautifulSoup(page.text, 'html.parser')第二个参数指定了 Beautiful Soup 会用来解析 HTML 文档的解析器。 soup variable now contains a BeautifulSoup 变量目前包含一个BeautifulSoup对象。这是使用 Python 内置的html.parser解析在 page.text中的 HTML 文档而生成的解析树。
现在,初始化一个包含了所有抓取的数据列表的变量。
quotes = []现在可以使用soup从 DOM 中提取元素,如下图所示:
quote_elements = soup.find_all('div', class_='quote')find_all() 方法将返回由 quote 类标识的所有<div> HTML 元素的列表。 换句话说,这行代码相当于应用 .quote CSS 选择器来检索页面上的 quote HTML 元素列表。然后您可以迭代 quotes列表以检索引用数据,如下图所示:
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)通过Beautiful Soupfind()方法,您可以提取感兴趣的单个 HTML 元素。由于与引用关联的标签不止一个,建议您将这些标签存储在一个列表中。
接着,您可以将此数据转换为字典并将其附加到quotes/引用列表,如下图所示:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)以这种字典格式存储提取的数据会更易于访问和理解。
以上内容介绍了如何从单个页面中提取所有引用数据。不过,目标网站由多个网页组成。现在,我们来了解如何抓取整个网站。
实现爬虫逻辑
在主页底部,您可以找到一个“Next →” <a> HTML 元素,它重定向到目标网站的下一页。除最后一页之外的其他页面都有包含此 HTML 元素。这种情况在各种分页网站中都很常见。
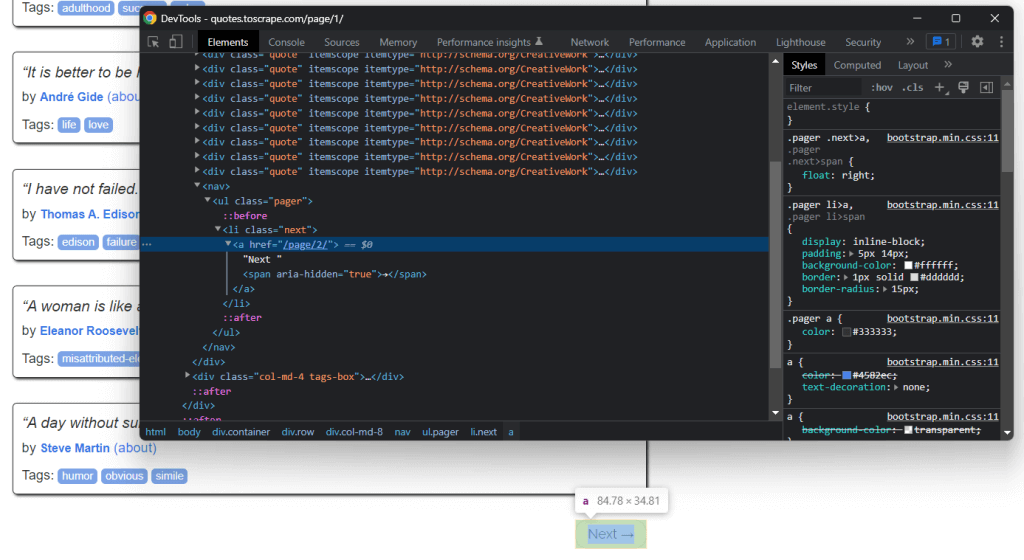
通过 “Next →” <a> HTML 元素中包含的链接,您可以轻松浏览整个网站。 那么,我们从主页开始,看看如何浏览完目标网站包含的每个页面。 您只需要查找 .next <li> HTML元素并提取指向下一页的相关链接。
您可以按下图所示实现爬虫逻辑:
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')这个 where循环会迭代每个页面,直到没有下一页。具体来说,它会提取下一页的相关 URL,并使用该URL创建要抓取的下一页的 URL。这样,就会下载下一页。接着会进行网页抓取并重复这个逻辑。
您刚刚了解了如何实施爬虫逻辑来抓取整个网站。现在我们来了解如何将提取的数据转换成更有用的格式。
将数据转换为 CSV 格式
我们来看看如何将包含抓取了引用数据的字典列表转换为 CSV 文件。您可以通过以下几行代码实现:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()此代码段将包含在字典列表中的引用数据写入 quotes.csv 文件中。请注意, csv 是 Python 标准库的一部分。因此,您可以导入并使用CSV,无需安装额外的依赖项。详细地说,您只需使用 open(). 然后,您可以使用csv库的Writer对象中的 writerow()函数填充文件。这一步会把每个引用字典以CSV格式行的形式写入 CSV 文件中。
到这一步,您将网站中包含的原始数据转变为存储在 CSV 文件中的结构化数据。数据提取过程结束,您现在可以查看整个 Python web scraper。
进行整合
这是完整的 Python 网页抓取脚本:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()如此处所述,您可以在不到 100 行代码中构建web scraper。这个 Python 脚本能够爬取整个网站,自动提取所有数据,并将其转换为 CSV 文件。
恭喜!您已经学习了如何使用 Requests 和 Beautiful Soup 库构建 Python web scraper!
运行网页抓取 Python 脚本
如果您是 PyCharm 用户,请点击下图所示按钮运行脚本:

或者,在项目目录内的终端中启动以下 Python 命令:
python scraper.py等待该过程结束,现在您可以访问 quotes.csv文件。打开该文件,应该包含以下数据:
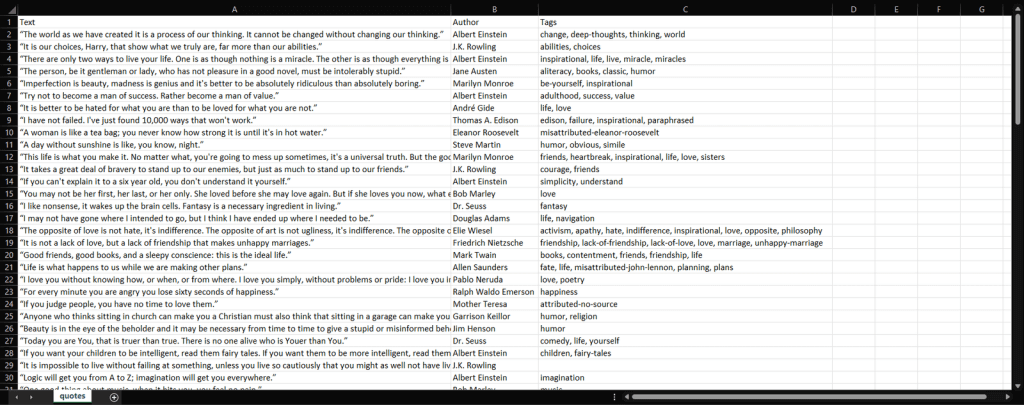
看!目标网站中包含的100 条引用现在都保存在了一个 CSV 文件中!
结论
在本教程中,您了解了网页抓取、使用 Python 前的准备工作,以及最好的网页抓取 Python 库。接着,通过真实示例,您了解了如何使用 Beautiful Soup 和 Requests 构建网页抓取应用程序。如您所知,只需几行代码就能使用 Python 进行网页抓取。
然而,网页抓取也会遇到阻碍。具体来说,反爬虫和反抓取技术越来越进步。这就是为什么您需要亮数据Bright Data提供的高级完整的自动化网页抓取工具。
为了避开网页屏蔽,我们建议根据您的用例从 Bright Data 提供的多种代理服务中选择代理。
常见问题
是的,网页抓取和爬取是更广泛的数据科学领域的一部分。抓取/爬取是从结构化和非结构化数据中派生出的所有副产品的基础。包括分析、算法模型/输出、洞察和“适用知识”。
使用 Python 从网站抓取数据需要检查目标 URL 页面,确定要提取的数据,编写并运行数据提取代码,最后以目标格式存储数据。
构建 Python 数据爬虫的第一步是利用字符串方法解析网站数据,然后使用 HTML 解析器解析网站数据,最后与必要表单和网站组件进行交互。