







Web Scraper IDE
![]()

- 73+Ready-made JavaScript functions
- 38K+ Scrapers built by our customers
- 195Countries with proxy endpoints

Easily bypass CAPTCHAs and Blocks
Our hosted solution gives you maximum control and flexibility without maintaining proxy and unblocking infrastructure. Easily scrape data from any geo-location while avoiding CAPTCHAs and blocks.
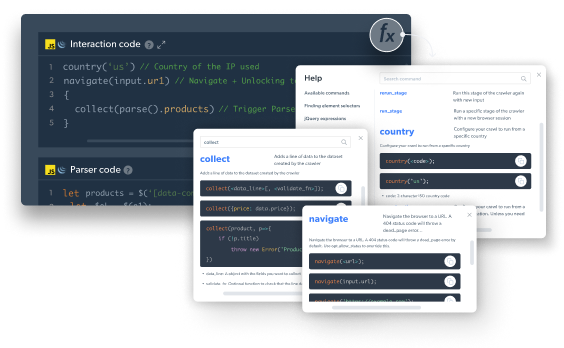
Use code templates and pre-built JavaScript functions
Reduce development time substantially by using ready-made JavaScript functions and code templates from major websites to build your web scrapers quickly and in scale.
Everything you need from a web scraping solution


Web Scraper IDE Features
Pre-made web scraper templates
Get started quickly and adapt existing code to your specific needs.
Interactive preview
Watch your code as you build it and debug errors in your code quickly.
Built-in debug tools
Debug what happened in a past crawl to understand what needs fixing in the next version.
Browser scripting in JavaScript
Handle your browser control and parsing codes with simple procedural JavaScript.
Ready-made functions
Capture browser network calls, configure a proxy, extract data from lazy loading UI, and more.
Easy parser creation
Write your parsers in cheerio and run live previews to see what data it produced.
Auto-scaling infrastructure
You don’t need to invest in the hardware or software to manage an enterprise-grade web data scraper.
Built-in Proxy & Unblocking
Emulate a user in any geo-location with built-in fingerprinting, automated retries, CAPTCHA solving, and more.
Integration
Trigger crawls on a schedule or by API and connect our API to major storage platforms.
Starting from $2.4 / 1000 page loads
- Pay as you go plan available
- No setup fees or hidden fees
- Volume discounts
Data collection process
To discover an entire list of a products within a category or the entire website, you’ll need to run a discovery phase. Use ready made functions for the site search and clicking the categories menu, such as:
- Data extraction from lazy loading search (load_more(), capture_graphql())
- Pagination functions for product discovery
- Support pushing new pages to the queue for parallel scraping by using rerun_stage() or next_stage()
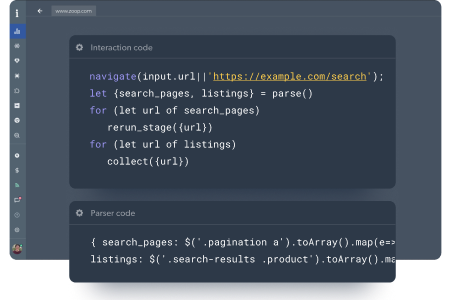
Build a scraper for any page, using fixed URLs, or dynamic URLs using an API or straight from the discovery phase. Leverage the following functions to build a web scraper faster:
- HTML parsing (in cheerio)
- Capture browser network calls
- Prebuilt tools for GraphQL APIs
- Scrape the website JSON APIs
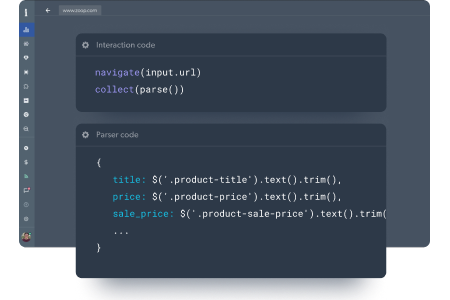
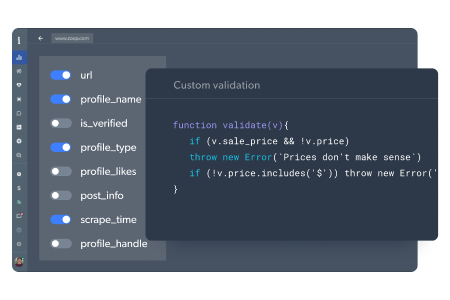
A crucial step ensuring you’ll receive structured and complete data
- Define the schema of how you want to receive the data
- Custom validation code to show that the data is in the right format
- Data can include JSON, media files, and browser screenshots
Deliver the data via all the popular storage destinations:
- API
- Amazon S3
- Webhook
- Microsoft Azure
- Google Cloud PubSub
- SFTP
Want to skip scraping, and just get the data?
Designed for Any Use Case
E-commercewebsite scraper
- Configure dynamic pricing models
- Identify matching products in real-time
- Track changes in consumer demand
- Anticipate the next big product trends
- Get real-time alerts when new brands are introduced
Social media website scraper
- Scrape likes, posts, comments, hashtags, & videos
- Discover influencers by # of followers, industry, and more
- Spot shifts in popularity by monitoring likes, shares, ect.
- Improve existing campaigns & create more effective ones
- Analyze product reviews and consumer feedback
Business website scraper
- Lead generation & jobs website scraper
- Scrape public profiles to update your CRM
- Identify key companies and employee movement
- Evaluate company growth and industry trends
- Analyze hiring patterns and in-demand skill sets
Travel, hospitality & tourism website scraper
- Compare prices of hotel & travel competitors
- Set dynamic pricing models in real-time
- Find your competitors new deals & promotions
- Determine the right price for every travel promotion
- Anticipate the next big travel trends
Real estate website scraper
- Compare properties pricing
- Keep an updated database of property listings
- Forecast sales and trends to improve ROI
- Analyze negative and positive rental cycles of the market
- Locate properties with the highest rental rates
Web Scraper Inspiration

Industry Leading Compliance
Our privacy practices comply with data protection laws, including the EU data protection regulatory framework, GDPR, and CCPA – respecting requests to exercise privacy rights and more.
Web scraper IDE Frequently Asked Questions
What is the Web Scraper IDE?
Web scraper IDE is a fully hosted cloud solution designed for developers to build fast and scalable scrapers in a JavaScript coding environment. Built on Bright Data’s unblocking proxy solution, the IDE includes ready-made functions and code templates from major websites – reducing development time and ensuring easy scaling.
Who is the Web Scraper IDE for?
Ideal for customers who have development capabilities (in-house or outsourced). Web Scraper IDE users have maximum control and flexibility, without needing to maintain infrastructure, deal with proxies and anti-blocking systems. Our users can easily scale and develop scrapers fast using pre-built JavaScript functions and code templates.
What does the Web Scraper IDE free trial include?
- unlimited tests
- access to existing code templates
- access to pre-built JavaScript functions
- publish 3 scrapers, up to 100 records each
**The free trial is limited by the number of scraped records.
In what format is the data delivered?
Choose from JSON, NDJSON, CSV, or Microsoft Excel.
Where is the data stored?
You can select your preferred delivery and storage method: API, Webhook, Amazon S3, Google Cloud, Google Cloud Pubsub, Microsoft Azure, or SFTP.
Why is it important to have an unblocking solution when web scraping?
Having an unblocking solution when scraping is important because many websites have anti-scraping measures that block the scraper’s IP address or require CAPTCHA solving. The unblocking solution implemented within Bright Data’s Web Scraper IDE is designed to bypass these obstacles and continue gathering data without interruption.
What kind of data can I scrape?
Publicly available data. Due to our commitment to privacy laws, we do not allow scraping behind log-ins.